Lockfree Programming: A Mental Model
Recently I decided to help a friend by coding up a special lockfree datastructure. Over my career, I’ve built and used a substantial number of lockfree datastructures. However, my friend has not and wanted to learn.
While poking around the internet, I noticed a lot of unfortunate advice. For some reason, at least in Computer Science, people tend to have an attitude of “it’s complex and scary so you should just stay away”. I’ve always been allergic to this framing. Every new and unfamiliar thing tends to start out as “complex and scary” before the collective brain of humanity finds the right cognitive framing. Usually, this takes a generation or two. At any rate, we shouldn’t avoid hard things just because they’re hard.
In particular, I find the literature on lockfree datastructures to have a “reference manual” problem. The content is available in great multitudes, but few people sit down to read a “reference manual” cover-to-cover. What’s missing is a framing / mindset / attitude towards the task. In this article, I’m going to build out a Mental Model for lockfree programming that is useful when creating or trying to understand lockfree datastructures.
Now, most discussions of lockfree programming dive directly into jargon such as atomic operations, load-acquire, store-release, sequential consistency, memory-synchronization-barriers, compare-and-swap atomics, strong-memory models, weak-memory models, etc etc etc. All that dry jargon is a great way to fall asleep, but I need you awake and alert!
Instead I’m going to start somewhere that few articles start: The Great Lie
The Great Lie of “One Big Machine”
Modern machines (2023) have a lots of cores. For example, a modern AMD Ryzen machine has 64 hardware cores. In a dual-socket configuration you can build a single machine with 128-cores. If you decide that Symmetric Multithreading (also known as Hyper-Threading) is helpful for your workload, you have 256 threads.
But how is such a computer organized?
A common, but naive and very incorrect model is this:
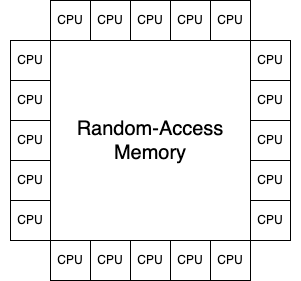
In reality, it actually looks more like this:
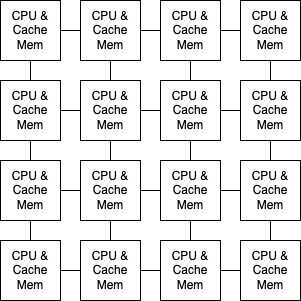
Why does this matter? Well, it means that you’re not programming a single computer. It means that you’re programming many individual computers that are tightly networked-together. In other words, you’re programming a supercomputer.
I think it’s more helpful to re-frame the problem in this light. Here’s a helpful mapping:
| Super-computer | Modern CPU |
|---|---|
| Cluster Node Processor | CPU Core |
| Cluster Node Memory | CPU Cache |
| Cluster Interconnect Fabric | NOC (Network On Chip) Mesh, QPI, Infinity Fabric, etc |
| Packet Frame | Cache Line |
| Maximum Transmission Unit (MTU) | Cache Line Size (64 bytes, 128 bytes, etc) |
msg_send(send_value) |
*pointer_to_shared = send_value |
recv_value = msg_recv() |
recv_value = *pointer_to_shared |
Armed with this analogy, it becomes much easier to understand why concurrent programming is so different. The reality is that you’re coding on-top of a hidden msg_send and msg_recv system where packets are actually cpu cache lines, and load/store instructions implicitly trigger send/recv operations. Normally one doesn’t think of a pointer deference as triggering some cross-network operation, but this is effectively what is happening.
When you're programming lockfree data-structures, it’s very important to keep this idea in your head. When, where, and how you dereference a pointer to shared state is critical.
One might wish that things were less “implicit”. For example: explicitly form an entire cache-line sized packet and broadcast it out. Unfortunately, the evolution of computing, with it’s unceasing desire for backwards-compatibility, has lead to the present day. For a small number of cores (dual-core, quad-core, etc), it’s not unreasonable to pretend there is one big shared RAM. But for large core count machines, the mental model become untenable.
Reasonable Behaviors
Armed with this new mental model, let’s go look at real programs running on this super-computer. With the “one big machine” idea, these behaviors may seem bizarre, but with our reframing, I think you’ll find them quite intuitive
1. Loads are frequently stale
int *ptr_to_shared;
void thread_1()
{
while (1) {
int data = *ptr_to_shared;
if (data != *ptr_to_shared) printf("This can and will happen.. often")
}
}
In single-threaded programming if we load some value from a pointer into a local, we expect that the local variable value IS the value behind the pointer. But, the pointer is to shared state on our super-computer. It’s a message receive operation and it’s not reasonable to consider subsequent reads being the same.
Reframing the code, it becomes clearer:
int *ptr_to_shared;
void thread_1()
{
while (1) {
int data = msg_recv(ptr_to_shared);
if (data != msg_recv(ptr_to_shared)) printf("This can and will happen.. often")
}
}
If you received two packets from a computer network, would you ever blindly assume they are identical? Hopefully not!
The conclusion here is that you should never expect data == *ptr_to_shared to be true. From the moment the load completes, you should assume it’s already stale.
2. Stores take time to propagate
int *ptr_to_shared_1; // init: *ptr_to_shared_1 == 0
int *ptr_to_shared_2; // init: *ptr_to_shared_2 == 0
void thread_1()
{
*ptr_to shared_1 = 1;
printf("value_2: %d\n", *ptr_to_shared_2);
}
void thread_2()
{
*ptr_to shared_2 = 1;
printf("value_1: %d\n", *ptr_to_shared_1);
}
It’s quite likely that we will get the output:
value_1: 0
value_2: 0
Reframing the code:
int *ptr_to_shared_1; // init: *ptr_to_shared_1 == 0
int *ptr_to_shared_2; // init: *ptr_to_shared_2 == 0
void thread_1()
{
msg_send(ptr_to shared_1, 1);
printf("value_2: %d\n", msg_recv(ptr_to_shared_2));
}
void thread_2()
{
msg_send(ptr_to shared_2, 1);
printf("value_1: %d\n", recv_msg(ptr_to_shared_1));
}
The msg_send and msg_recv are NOT synchronous and with the speed of light being finite, we have a very simple truth: delay exists. Think of msg_send as posting a network packet. Where is this packet after posting? Many possibilities: in the outgoing send queue, physically on the wire, in the destination recv queue, etc. Except we would use different terminology: CPU load/store queue, cache coherency protocol, etc.
The takeaway here is (1) stores take time, and (2) loads and stores are asynchronous. Being asynchronous sounds annoying. Why not make everything synchronous? Imagine this for a second. Every operation on memory would require coordination with all CPUs on this great big super-computer. This is akin to a big global lock. What’s the point of having so many CPUs if they are just sitting around waiting for their turn to exclusively do work.
Asynchrony is The Way.
4. Reordering
int *ptr_to_shared_1; // init: *ptr_to_shared_1 == 0
int *ptr_to_shared_2; // init: *ptr_to_shared_2 == 0
void thread_1()
{
*ptr_to shared_1 = 1;
*ptr_to shared_2 = 1;
}
void thread_2()
{
printf("value_1: %d\n", *ptr_to_shared_1);
printf("value_2: %d\n", *ptr_to_shared_2);
}
We can get the output:
value_1: 0
value_2: 1
Each msg_send and msg_recv can have an independent delay. Consider our network analogy: some packets may take different paths and get reordered.
Fences bring Order to Chaos
How do we make sense out of this chaos? Causality is Key.
Modern machines have various mechanisms to make these msg_send and msg_recv operations less asynchronous at the expense of performance. As we noted previously, full synchrony would defeat the point of multi-core, so we want to think carefully about how much synchrony we need.
By trading some asynchrony for synchrony, we can buy something very important: Causality!
The most common reorderings
Consider this program:
int *ready_flag; // init: *ready_flag == 0
data_t *data; // init: ???
void writer_thread()
{
*data = do_some_work_to_produce_data();
*ready_flag = 1;
}
data_t reader_thread()
{
while (1) {
int ready = *ready_flag;
if (ready) break;
}
return *data;
}
Here, the reader_thread wants to wait for some data produced by do_some_busy_work_to_produce_data
We have no reason to suspect this will work since (as discussed above), we can have reordering.
Let’s reframe this example:
int *ready_flag; // init: *ready_flag == 0
data_t *data; // init: ???
void writer_thread()
{
msg_send(data, do_some_work_to_produce_data());
msg_send(ready_flag, 1);
}
data_t reader_thread()
{
while (1) {
int ready = msg_recv(ready_flag);
if (ready) break;
}
return msg_recv(data);
}
It’s now easier to see two possible reorderings:
- Our
msg_sendcould reorder in thewriter_thread - Our
msg_recvcould reorder in thereader_thread
Let’s invent for a moment some mechanism that could suppress these reorderings.
Consider:
int *ready_flag; // init: *ready_flag == 0
data_t *data; // init: ???
void writer_thread()
{
msg_send(data, do_some_work_to_produce_data());
msg_send_fence();
msg_send(ready_flag, 1);
}
data_t reader_thread()
{
while (1) {
int ready = msg_recv(ready_flag);
msg_recv_fence();
if (ready) break;
}
return msg_recv(data);
}
Here we invented msg_send_fence and msg_recv_fence to prevent the re-orderings. You can imagine the CPU stalling on these fences, waiting until the msg_send or msg_recv are completed.
These inventions are similar to the real thing:
msg_send_fence⇒store_releasemsg_recv_fence⇒load_acquire
When someone mentions Acquire and Release Semantics, this is what they’re talking about.
Let’s translate the code back:
int *ready_flag; // init: *ready_flag == 0
data_t *data; // init: ???
void writer_thread()
{
*data = do_some_work_to_produce_data();
STORE_RELEASE();
*ready_flag = 1;
}
data_t reader_thread()
{
while (1) {
int ready = *ready_flag;
LOAD_ACQUIRE();
if (ready) break;
}
return *data;
}
The actual semantics are stronger than our invention:
LOAD_ACQUIRE()⇒ Loads beforeLOAD_ACQUIREcannot reorder with Loads & Stores after itSTORE_RELEASE()⇒ Loads & Stores beforeSTORE_RELEASEcannot reorder with Stores after it
Notice what these don’t prevent:
LOAD_ACQUIRE()⇒ Stores beforeLOAD_ACQUIREcan reorder with anything afterSTORE_RELEASE()⇒ Loads afterSTORE_RELEASEcan reorder with anything before
Why these?
Simply put, Modern CPUS get a lot of performance out of hoisting loads. Loading memory can be very expensive, so CPUs go to great lengths to load data as soon as possible. They will even speculate on the memory needed. Doing so allows the memory delay to overlap with other operations and hopefully prevent stalling the CPU to wait for it once it is actually needed.
By contrast, CPUs care little about propagating Stores. High latency on commiting stores to main memory would not delay the local CPU. The general goal is: (1) start Loads sooner, (2) finish Stores later.
Notice that the LOAD_ACQUIRE and STORE_RELEASE fences do not inhibit these critical operations unless they are absolutely required. We allow Stores to drop down past a LOAD_ACQUIRE and we allow Loads to lift up above a STORE_RELEASE
Luckily, a lot of interesting lockfree code can be correctly constructed with just these. In fact, it's such a nice point in the tradeoff curve, that some machines act like LOAD_ACQUIRE and STORE_RELEASE barriers are everywhere (e.g. x86-64 for most operations).
However, sometimes more is needed.
The less common reorderings
Let’s return to a previous example:
int *ptr_to_shared_1; // init: *ptr_to_shared_1 == 0
int *ptr_to_shared_2; // init: *ptr_to_shared_2 == 0
void thread_1()
{
*ptr_to shared_1 = 1;
int val = *ptr_to_shared_2;
printf("value_2: %d\n", val);
}
void thread_2()
{
*ptr_to shared_2 = 1;
int val = *ptr_to_shared_1;
printf("value_1: %d\n", val);
}
We explained above that the following output is possible:
value_1: 0
value_2: 0
Let’s try to understand why our LOAD_ACQUIRE and STORE_RELEASE barriers won’t help
Consider this:
int *ptr_to_shared_1; // init: *ptr_to_shared_1 == 0
int *ptr_to_shared_2; // init: *ptr_to_shared_2 == 0
void thread_1()
{
*ptr_to shared_1 = 1;
LOAD_ACQUIRE();
STORE_RELEASE();
int val = *ptr_to_shared_2;
printf("value_2: %d\n", val);
}
void thread_2()
{
*ptr_to shared_2 = 1;
LOAD_ACQUIRE();
STORE_RELEASE();
int val = *ptr_to_shared_1;
printf("value_1: %d\n", val);
}
But..
- A load can reorder above a
STORE_RELEASEfence, and - A store can reorder below a
LOAD_ACQUIREfence, and - A load and store with no fences between them are completely asynchronous and have any order
So, we could get this ordering:
int *ptr_to_shared_1; // init: *ptr_to_shared_1 == 0
int *ptr_to_shared_2; // init: *ptr_to_shared_2 == 0
void thread_1()
{
LOAD_ACQUIRE();
int val = *ptr_to_shared_2;
*ptr_to shared_1 = 1;
STORE_RELEASE();
printf("value_2: %d\n", val);
}
void thread_2()
{
LOAD_ACQUIRE();
int val = *ptr_to_shared_1;
*ptr_to shared_2 = 1;
STORE_RELEASE();
printf("value_1: %d\n", val);
}
Uh oh! We need a new barrier to prevent this problem. Let’s call it MEM_FENCE and specify that it prevents all reorderings.
So, we have:
int *ptr_to_shared_1; // init: *ptr_to_shared_1 == 0
int *ptr_to_shared_2; // init: *ptr_to_shared_2 == 0
void thread_1()
{
*ptr_to shared_1 = 1;
MEM_FENCE();
int val = *ptr_to_shared_2;
printf("value_2: %d\n", val);
}
void thread_2()
{
*ptr_to shared_2 = 1;
MEM_FENCE();
int val = *ptr_to_shared_1;
printf("value_1: %d\n", val);
}
In practice, this fence has many names:
- A Full Memory Barrier
- C++ atomics sequential-consistency fence
- GCC:
__sync_synchronize() - x86-64:
mfenceinstruction - ARM:
dmbinstruction - PowerPC:
hwsyncinstruction
Conclusion
As you can see, things seem far less scary and mystifying when you view a modern machine as a super-computer of many independent machines on a fast interconnect network. The operations one thinks about while doing lockfree programming is the series of msg_send and msg_recv operations across this “interconnect”. These operations are highly asynchronous. But, it’s quite straight-forward to enforce some order and structure to this chaos. Whenever things get a tad confusing, it’s quite easy to translate into the msg_send and msg_recv framing and think instead about network messages.
My original goal in writing was to communicate some practical advice and “guidelines” for successful lockfree programming. But when I sat down to write that, I quickly realized that a Mental Model needed to be developed first in order to frame the subject correctly. In the next (hypothetical) post, I’d like to return to that original goal and give some practical advice.